
Getting Started with Ollama & Semantic Kernel
Hi Everyone! This post is continuation of a series about Semantic Kernel. Over the time, I will updated this page with links to individual posts :
Getting Started with Semantic Kernel (Part 1)
Getting Started with Semantic Kernel (Part 2)
Building Blocks of Semantic Kernel
Getting Started with Foundry Local & Semantic Kernel
This Post - Getting Started with Ollama & Semantic Kernel
Getting Started with LMStudio & Semantic Kernel
Now, we have a basic understanding how to integrate with local LLM using Semantic Kernel. In this post we will continue our journey with another local LLM tool Ollama.
What is Ollama?
Ollama is the high performance and headless application that is designed to run LLM on your own hardware. It supports both GPU & CPU. It is based on llama.cpp. Since v0.7.0, it supports multimodal models, models which can process both text, images and audio.
Ollama maintains a catalog of models that are optimized and customized for the application. However, you can use any GGUF models from Hugging Face. I will write another post on how to use Ollama with Hugging Face models but In this post, we use the models available in the catalog.
Ollama is available for Windows, Linux and MacOS. We will be using Windows for this post.
Installing Ollama
You can install ollama, either using the installer or using the docker image. I will be using the installer for this post but will also show you how to use the docker image.
Installation using Docker
CPU Only
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
GPU Only
To enable Nvidia GPU support for Docker Desktop, make sure all prerequisites are met. You can check the Docker for more information.
You also need to make sure you have Nvidia container toolkit installed.
Once you have all the prerequisites, you can run the following command to start the Ollama container with GPU support:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Installation using Installer
You can download the installer from official website Ollama. Based on your OS, you can download the installer. Once downloaded, run the installer and follow the instructions to install Ollama.
Alternatively, you can download the installer from the Ollama Github Repo.
List Available Models
Based on, how you installed it ollama command will be available either in your windows terminal or docker container. You can use the following command to list all available models:
ollama list
Just after the installation, you will see no models available.
Run your first model
To run your first model, you can use the following command:
ollama run <model_name>
For example, to run the qwen3:0.6b model, you can use the following command:
ollama run qwen3:0.6b
Once you run the command, under the hood, it will download the model in your local machine and keep it C:\Users\%USERNAME%\.ollama\models and can be used for future reference.
If you want to download the model without running it, you can use the following command:
ollama pull <model_name>
If you want to change the model directory location, you can set the OLLAMA_MODELS environment variable to the desired path. Once set make sure to restart the application.
You can also expose the model as a REST API using the following command:
ollama serve
This will expose OpenAI API compatible endpoint on http://localhost:11434. You can use this endpoint from your semantic kernel application.
Setup Semantic Kernel
We will create a new minimal api project using your favorite IDE. I will be using Visual Studio.
- Open Visual Studio and create a new project.
- Select “ASP.NET Core Web API” template.
- Configure the project name and location.
- Click “Create” to generate the project.
It could be a console application as well, but I prefer to use minimal api as we will be using it from out chat application.
It gets interesting from here. As Ollama serves OpenAI compatible API, we can use the same code we used for Foundry Local.
Ollama also has a first class support in .NET using a awesome project called OllamaSharp. Based on this project, Semantic Kernel has also has dedicated connector for Ollama.
Add Nuget Packages
First, we need to install following nuget packages:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<Project Sdk="Microsoft.NET.Sdk.Web">
<PropertyGroup>
<TargetFramework>net9.0</TargetFramework>
<Nullable>enable</Nullable>
<ImplicitUsings>enable</ImplicitUsings>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.AspNetCore.OpenApi" Version="9.0.5" />
<!-- 👇 Use this package if you want to use OpenAI compatible API -->
<PackageReference Include="Microsoft.SemanticKernel.Connectors.OpenAI" Version="1.54.0" />
<!-- 👇 Use this package if you want to use OllamaSharp compatible API -->
<PackageReference Include="Microsoft.SemanticKernel.Connectors.Ollama" Version="1.54.0-alpha" />
</ItemGroup>
</Project>
Add Connector and Kernel
Next step is to add the OpenAI connector and Kernel to the ServiceCollection in Program.cs file. You can use the following code to do that:
1 |
|
Notice that the endpoint is different for different connectors.
Add Chat Completion Endpoint
Next step is to add the chat completion endpoint to the Program.cs file. You can use the following code to do that:
1 |
|
Let’s break down the code:
- We are using
MapPostto create a new endpoint/api/chatthat will handle chat requests. - We are using
text/event-streamto set the response type for streaming, which is used for server-sent events. - We are using
IChatCompletionServiceto get the chat service for the model we are using from Kernel. - We are using
ChatHistoryto keep track of the chat history based on per session. Initially, we are setting the system message toYou are helpful assistant.. Notice that, we are using global variablechatHistoriesfor demo purpose, later post we will use a better approach to manage the chat history. - We are using
AddUserMessageto add the user message to the chat history. - We are using
GetStreamingChatMessageContentsAsyncto get the streaming chat message contents from the LLM. - We are using
JsonSerializerto serialize the response and send it back to the client. - Finally, we are using
AddAssistantMessageto add the assistant message to the chat history. So that follow up questions can be asked. - We are using
cancellationTokento cancel the request if needed.
Let’s see it in action.
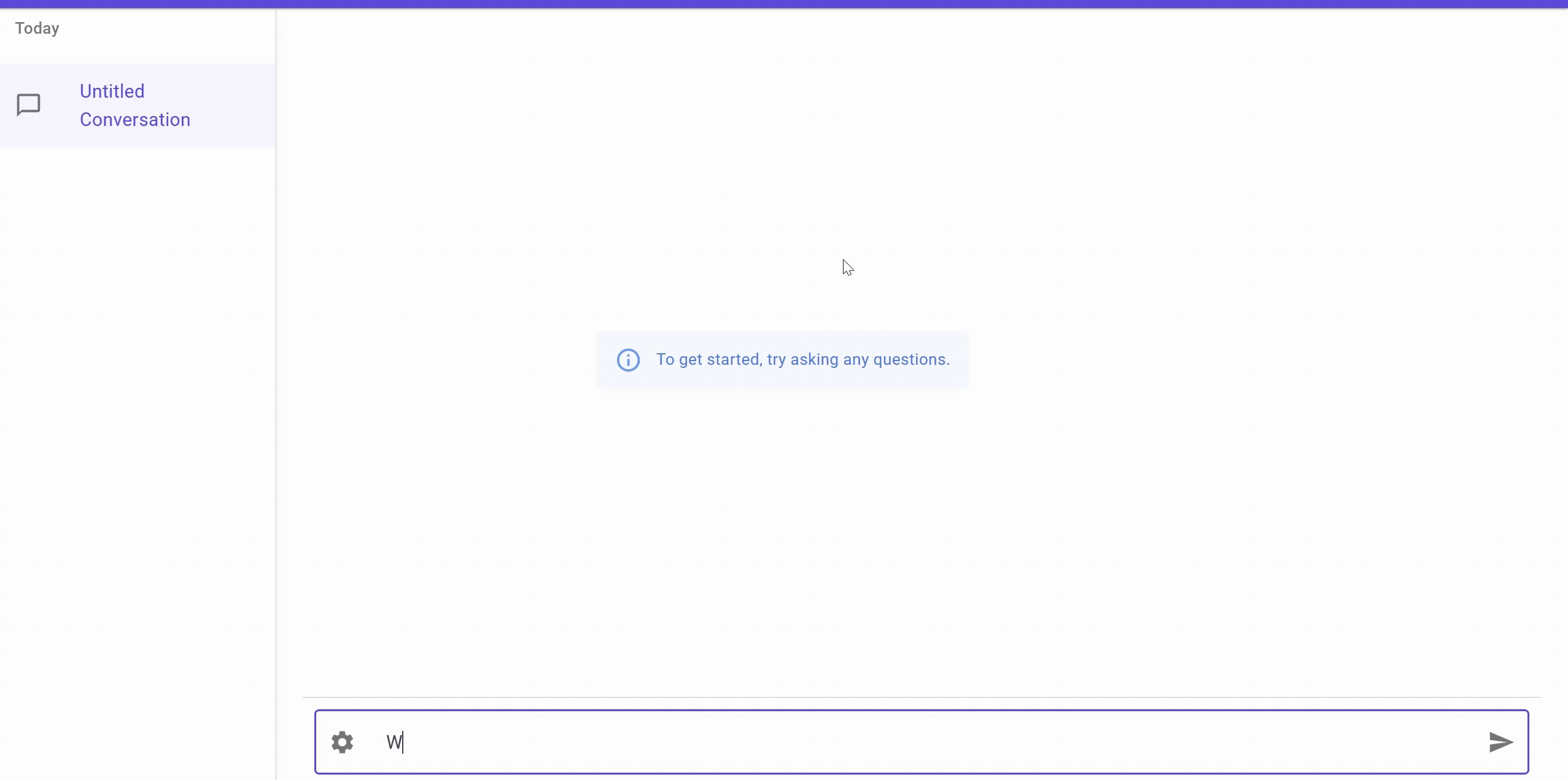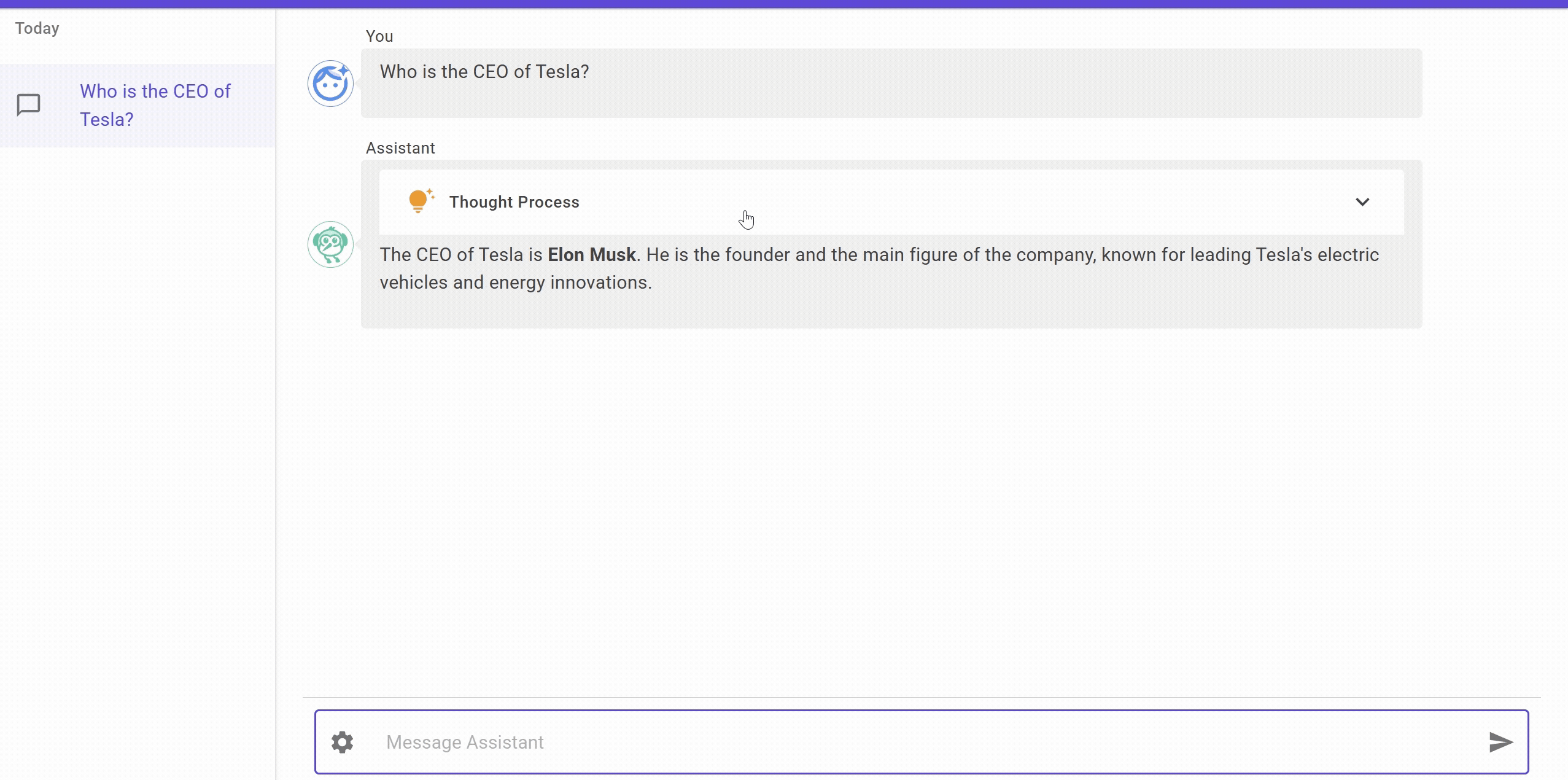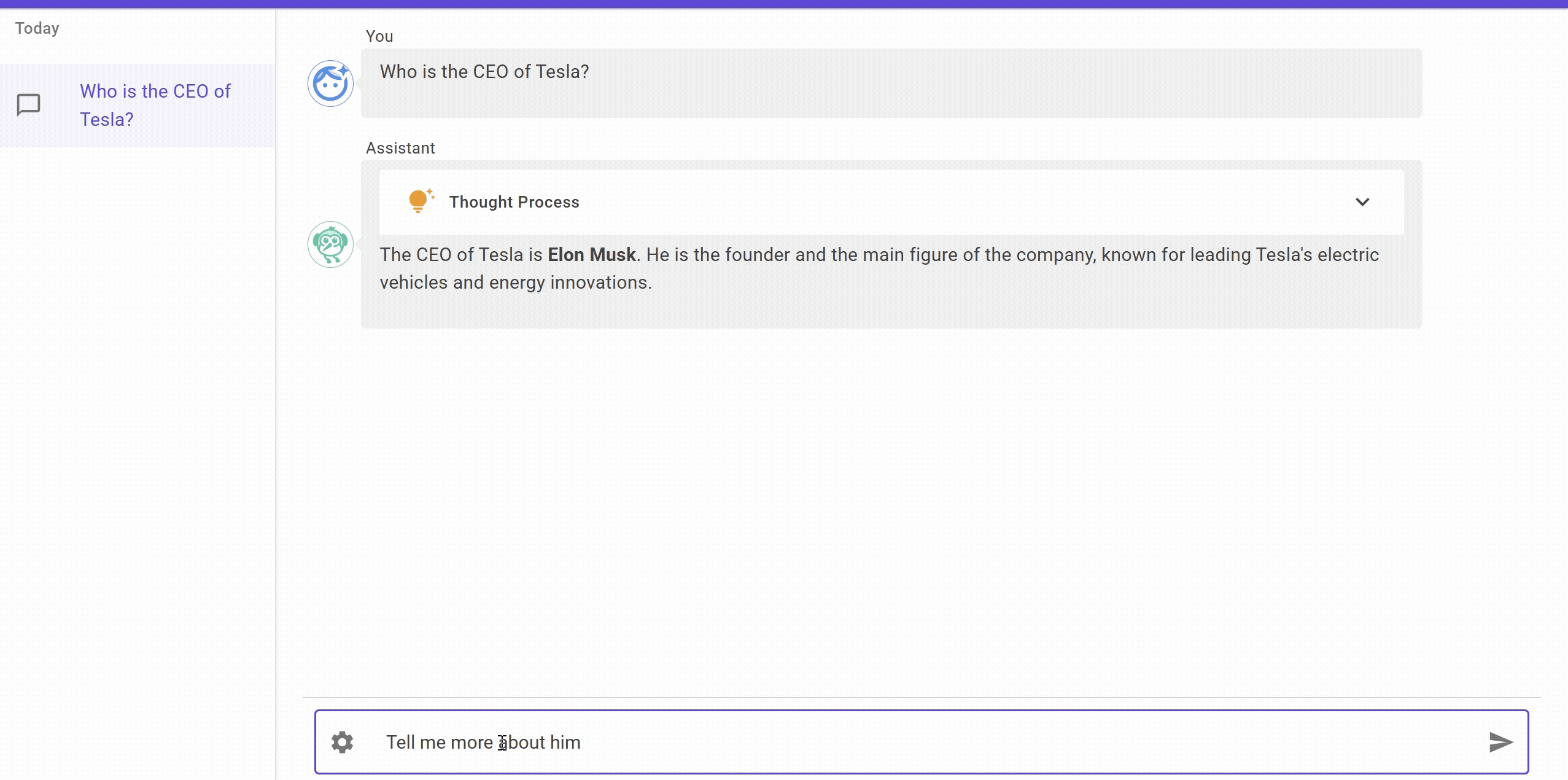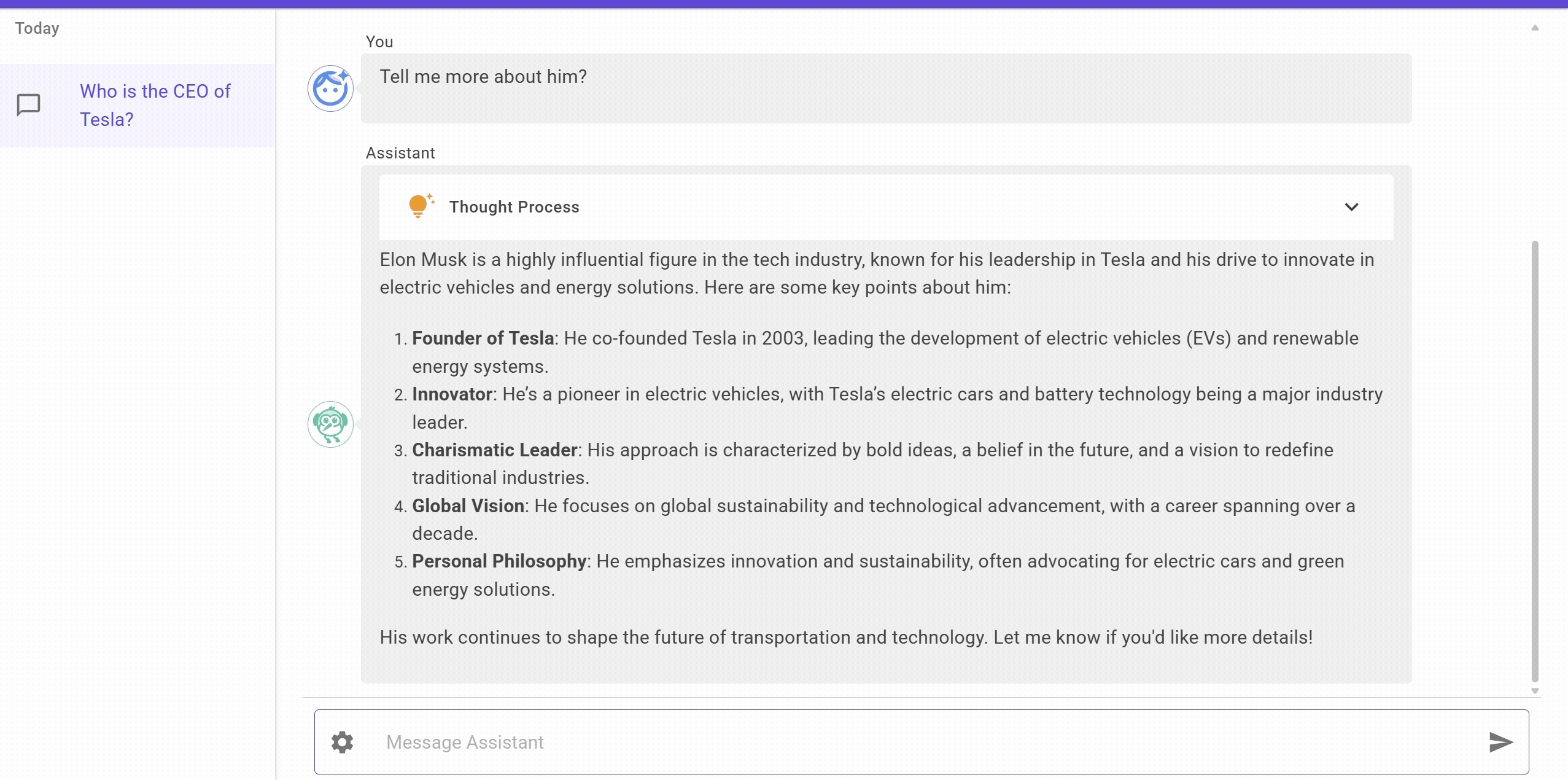
The UI is a chat application built using Blazor which supports thinking step as well, will explain it in detail in some future post. For now, you can see that we are able to get the response from the LLM using Ollama and Semantic Kernel.
Probably, you have noticed that the follow up question do not makes sense if the user is not providing any context. Since we are using ChatHistory to keep track of the chat history, we can use it to provide context to the LLM.
Outro
In this post, we have discussed how to use Ollama with Semantic Kernel. We have seen how to install Ollama, run a model, and use it with Semantic Kernel.
Will I be using Ollama in my future posts? For Chat completion and text embeddings, we will be using (Ollama team is working to support streaming with function call, releated discussion can be found here and as soons as it is available, I will update this post.
Next post will talk about LM Studio. We will see how to use it with Semantic Kernel and build a chat application.
