
Sync Cached Data Between Azure Function Instances Using FusionCache
In today’s event-driven programming world, we are using lots of Azure Function as the serverless solution that allows us to write less code, maintain less infrastructure, and save on costs.
Azure Function comes with various triggers such as HttpTrigger, ServiceBusTrigger, SqlTrigger etc. which help us build an API easily.
Let’s say the team already built a HttpTrigger API GetProductsById and the data is coming from Azure SQL. This API is exposed internally and n number of internal teams are using it maybe in batches with multiple products or a single product with multiple calls. The owner of this API is unaware of how this API is being used.
The Problem
The problem with this API is that it is not performant enough to meet the expectations even if they have enabled auto-scaling. The team started investigating the issue and noted below points -
- The data does not change very frequently.
- The requirement is if it gets updated it has to be mirrored as soon as possible.
- Based on this requirement, team wrote a query using Dapper to fetch the data directly from the database, which means no matter what, every time someone invokes the endpoint it always hit the database.
Let’s see how the function looks now -
1 |
|
The Solution
Team found a possible solution. As the data doesn’t change frequently, team decided to cache the data in memory, something like -
1 |
|
Locally, everything seems super fast. However, when testing this solution on Azure, team soon realised that it had several flaws.
When a single instance of Azure Function App running
Team noticed that the database is getting hit more than expected when the system is under pressure. The possible reason for such a problem is that _memcache.GetOrCreateAsync is getting executed in parallel at the same time. You may call this as Cache stampede.
When more than one instance of Azure Function App running (Horizentally Scalled)
Along with the previous problem, each instance is now having a cold start problem which means it hits the database again to fetch the data.
When Azure Function App is restarted
Same as above as the memory cache is empty it hits the database and so on.
SemaphoreSlim to rescue (Oops!)
Now, to solve the first problem team decided to use SemaphoreSlim which limits the number of threads that can access a resource or pool of resources concurrently. But this solves the problem partially because it might happen that product id 2 is waiting for product id 1. So a better approach is to have SemaphoreSlim but with a key.
Distributed Cache to rescue (sort of!)
To solve the second and third problems, we can’t only depend on memory cache we will need a second level of distributed cache where we could have data before we reach to database. The ideal solution could be to have a hybrid cache which first checks in memory, if not found checks the distribued cache, if not found fetches data from the database.
Problem with ideal solution
While the ideal solution makes more sense, it may create a problem while horizontally scaling. Memory cache could be out of sync very quickly when data changes in database/distributed cache but the memory cache is not expired.
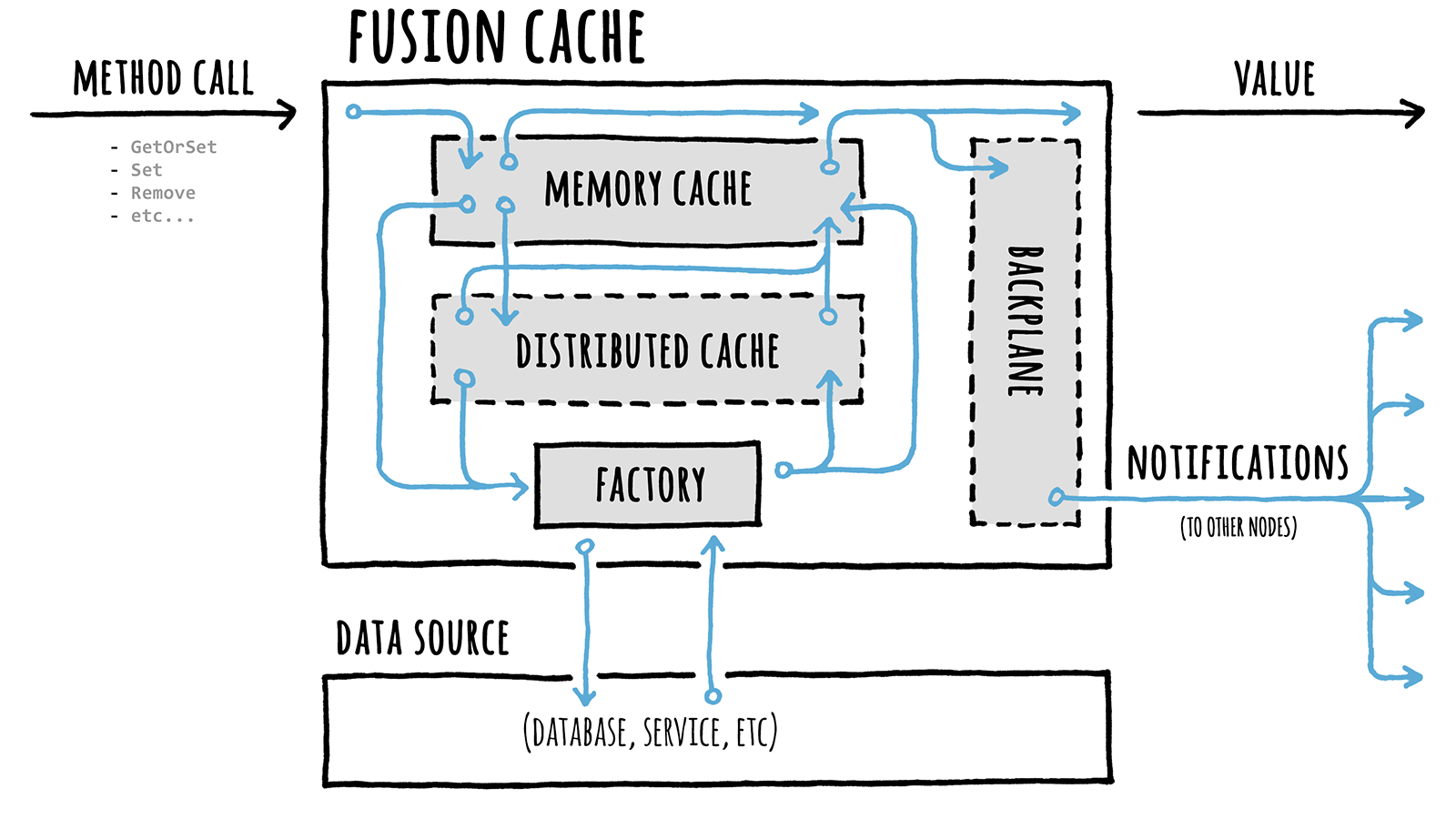
FusionCache to rescue (🎉Yay!🎉)
All of the above problems can be solved using FusionCache, a feature-rich, fully documented perfect caching solution available in .NET ecosystem.
FusionCache by default handles Cache stampede problem. It has many features but to keep it short we will only use two of it’s features.
- 2nd level: This feature creates a bridge between the memory cache and the distributed cache.
- Backplane: This feature notifies the other nodes about changes in the cache, so all will be in-sync.
Below is the visual representation -
Let’s update Program.cs to enable FusionCache
1 |
|
Also, update our function’s code -
1 |
|
The above codeblocks makes sure all cross cutting concerns such as cache stampede prevention,transient failure of distributed cache/backplane etc.
Till this point, we haven’t talked about updating the data, but one of our requirements is to reflect the updated data as soon as possible in all nodes.
To achieve this, we have several options. One of the options could be to add an interceptor somehow while updating the data. The other option could use the feature of SQL Server known as Change Tracking, which works with Azure Function’s SqlTrigger very well.
In this demo, I am using AdventureWorks Lite database which you can also download from here.
Let’s enable the Change Tracking at database level first and enable it for the table for which you want to track the change.
1 |
|
Let’s add our SqlTrigger function which could be a separate Function App altogether.
1 |
|
Essentially, when it expires the data from this function, first it removes the data from the distributed cache and it notifies all the available nodes to remove the data for that particular key from their memory cache through backplane.
Conclusion
You might have several types of data to cache and you don’t want to handle them in a single place, then the other approach could be to publish the update in eventhub and each consumer will invalidate their cached data.
Nevertheless, IMO, the above approach makes the developer’s life easy without worrying too much. It comes with a cost as Azure Redis is too costly.
Let me know what you think about this!
