
Building Smart Agents with LM Studio: A Complete Walkthrough of the Microsoft Agent Framework and /v1/responses API
In my previous post, Getting Started with LM Studio & Agent Framework for .NET Developers, we built a simple yet capable smart agent using Microsoft’s Agent Framework and LM Studio as local llm inference engine.
Now, there’s exciting news: LM Studio 0.3.29 has been released as a stable build — and it introduces full support for OpenAI’s /v1/responses API through the LM Studio REST server.
This new API unlocks a major step forward for developers building intelligent agents locally. It enables context retention across multiple interactions, seamless multi-turn conversations, and even remote tool usage — all through a unified interface.
In this post, we’ll dive into how to use the /v1/responses API inside LM Studio together with the Microsoft Agent Framework to build context-aware, tool-enabled agents. We’ll break down how previous_response_id works, show practical examples, and explore how you can turn simple chatbots into persistent, smart conversational systems.
Recap: Chat Completions API
Before we jump into the Responses API, let’s quickly recap how the traditional Chat Completions API offers.
-
You supply a list of message objects (e.g. role “user” / “assistant” / “system”).
-
The model returns a next message (or a completion) as a response.
-
You must yourself maintain the conversation history (i.e. store messages client-side or in a database).
-
It is stateless on OpenAI’s/server side — each request is independent.
-
Tool integration (if needed) must be orchestrated by your application (i.e. call APIs, wrap them, feed results back into chat).
It is simple, straightforward, and works well for many classic chatbot / conversational assistant scenarios.
Understanding the Responses API
The Responses API is a newer interface OpenAI is pushing as a more expressive, capable primitive for conversational and agentic use cases. It is designed to give developers higher-level building blocks for workflows that go beyond simple chat, especially when tool use, structured reasoning, or modality mixing is involved.
Key features of the Responses API include:
-
Server-managed state / conversation context You can pass a
previous_response_idrather than always sending full message history, simplifying context tracking. -
Native support for tool / function calling Unlike pure chat, Responses supports built-in or custom tools (e.g. web search, file lookup, code execution) more directly.
-
Streaming and synchronous modes You can choose to stream partial outputs or get a composed full response.
-
Reasoning control You can configure “reasoning effort” or parse reasoning output in models that support it.
-
Mixed modalities Responder interactions may include image inputs/outputs where supported (depending on model).
-
Backward compatibility OpenAI intends to maintain support for Chat Completions for simpler use cases, even as Responses becomes a more powerful option.
LM Studio & Responses API: What’s New in v0.3.29
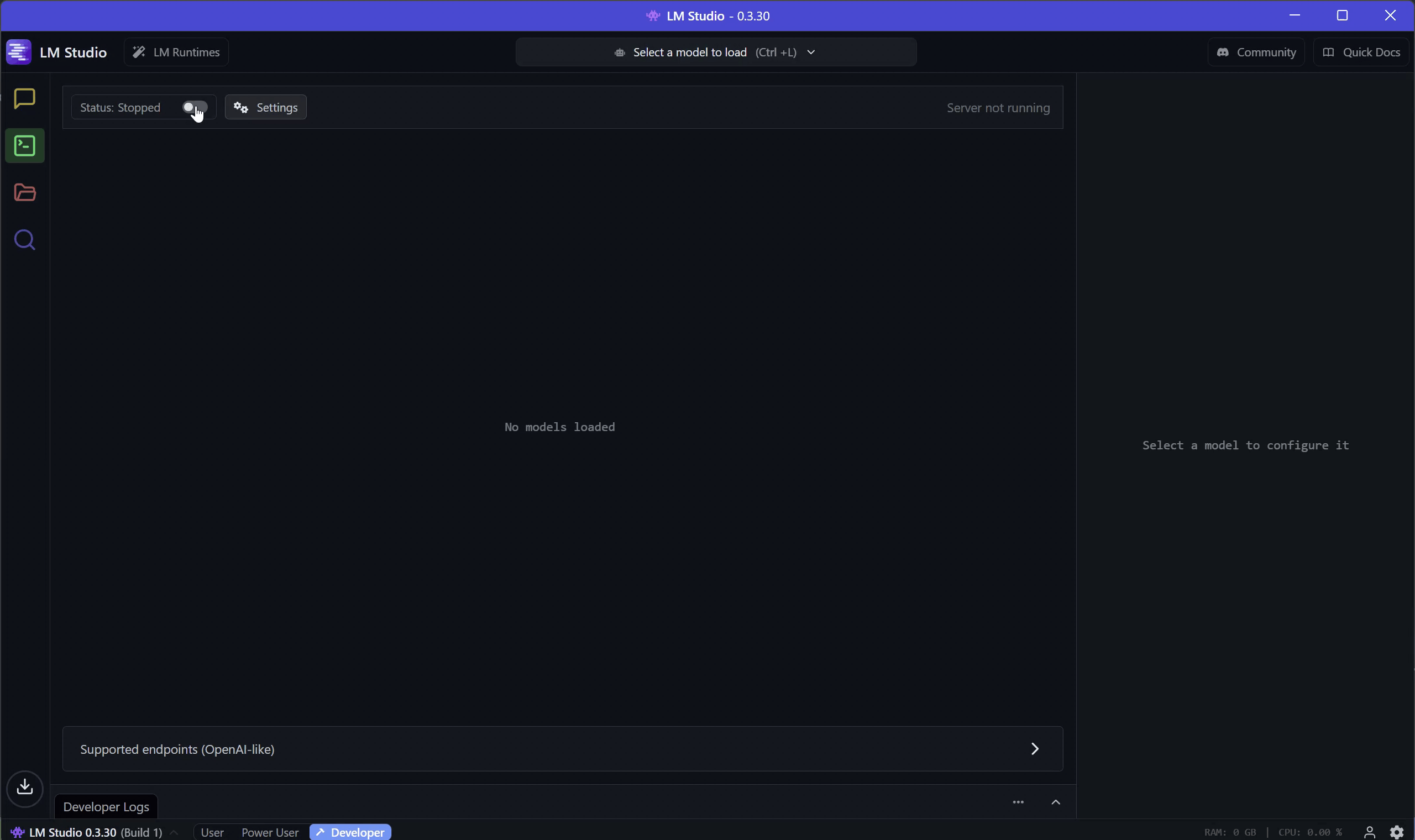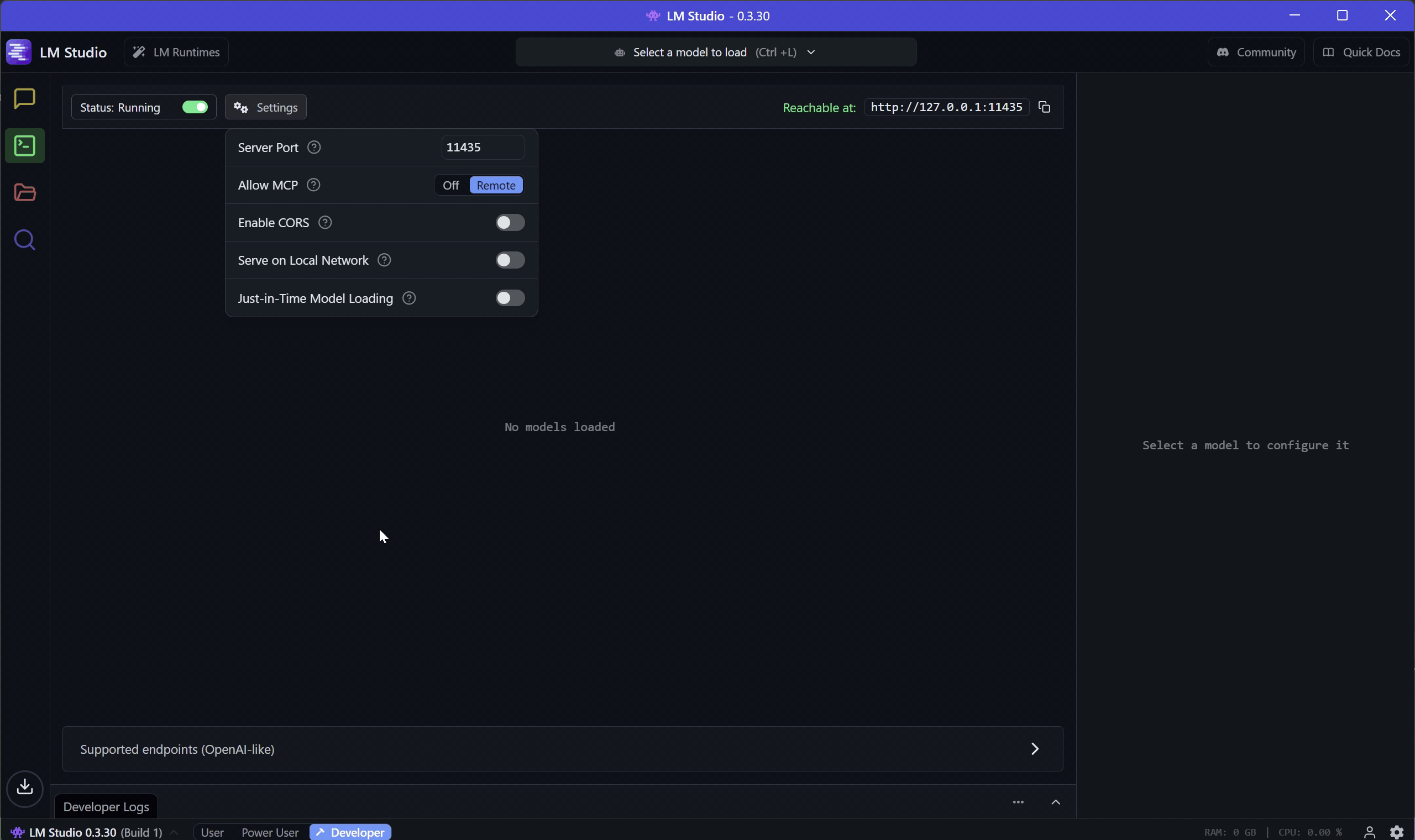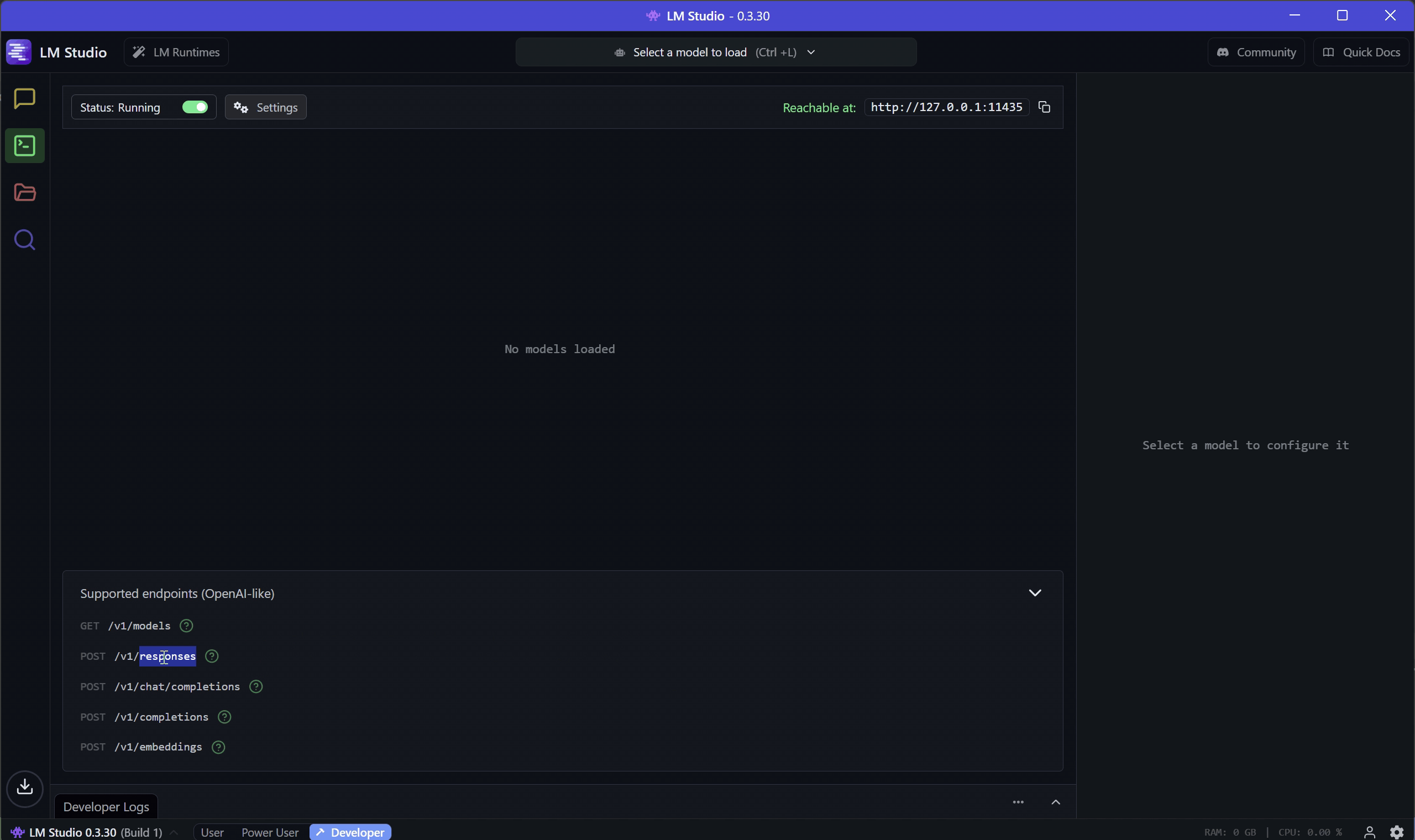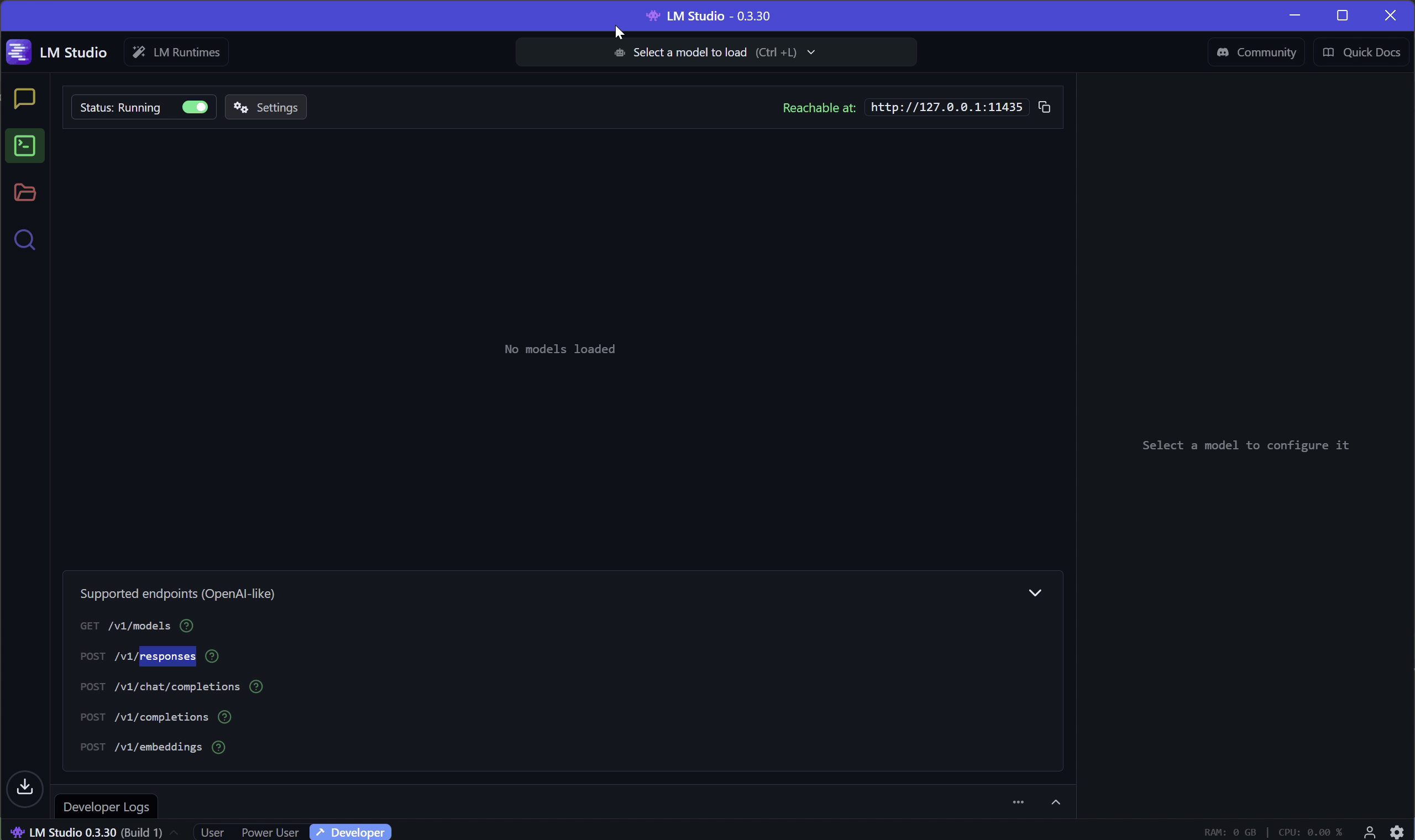
Here’s where LM Studio enters the picture: as of version 0.3.29, LM Studio has added support for the OpenAI-compatible /v1/responses API endpoint.
This integration means that if you run OpenAI’s OSS models locally through LM Studio, you can expose them using the same API semantics as OpenAI’s Responses. This brings several advantages:
-
Stateful interactions You can pass a
previous_response_idto continue a conversation without the client needing to track full message history. -
Custom function (tool) calling You can define your own function tools locally, similar to the function-calling features in Chat Completions or Responses. LM Studio
-
Remote MCP (Model Capability Proxy) usage LM Studio can optionally call tools from remote MCP servers (if you enable that in settings), so even your local model can leverage remote tool backends. LM Studio
-
Reasoning support and effort control For models like openai/gpt-oss-20b, you can parse reasoning output and configure the “effort” level (low / medium / high) for reasoning computation. LM Studio
-
Streaming or synchronous modes You may choose stream: true (receiving SSE events for incremental output) or not (just a JSON reply).
Now that we’ve explored what the Responses API is, how it differs from the Chat Completions API, and how LM Studio 0.3.29 brings this functionality to local models, let’s take it a step further.
In the next section, I’ll walk through a hands-on implementation that demonstrates how to use the Responses API (either via LM Studio locally or OpenAI’s cloud endpoint) inside Microsoft’s Agent Framework. This practical example shows how you can build a stateful, reasoning-aware AI agent capable of streaming intermediate reasoning steps, remembering previous interactions, and switching effortlessly between local and hosted models — all with just a few lines of C# code.
Practical Example: Building a Context-Aware Agent
Before you begin, make sure you have:
-
LM Studio 0.3.29 or later 👉 Download from LM Studio
Run it locally, and enable its HTTP server via the Developer tab.
- A model that supports the /v1/responses endpoint (e.g.
openai/gpt-oss-20b).
This will expose OpenAI API compatible endpoint on http://localhost:11435. Copy or note the server URL — you’ll use it in your application.
Create a .NET Console Application
Now, let’s create a simple .NET console application that uses the Microsoft Agent Framework to interact with a local LLM via LM Studio.
- Open your terminal or command prompt. Create a new console app targeting .NET 10:
dotnet new console -n AgentFrameworkLMStudioDemo -f net10.0 cd AgentFrameworkLMStudioDemo - Add the necessary NuGet packages for Microsoft Agent Framework and any other dependencies:
dotnet add package Microsoft.Agents.AI.OpenAI - Restore the packages:
dotnet restore
Write Your Agent
Open the Program.cs file and replace its contents with the following code:
using Microsoft.Agents.AI;
using OpenAI;
using OpenAI.Chat;
using System.ClientModel;
var endPoint = Environment.GetEnvironmentVariable("OPENAI_ENDPOINT") ?? "http://localhost:11435/v1";
var apiKey = Environment.GetEnvironmentVariable("OPENAI_API_KEY") ?? "apiKey";
var model = Environment.GetEnvironmentVariable("OPENAI_MODEL") ?? "openai/gpt-oss-20b";
const string AgentName = "Math Teacher";
const string AgentInstructions = "You are my math teacher.";
// Create an OpenAI Response Client that supports the Responses API
#pragma warning disable OPENAI001
var chatClient = new OpenAIClient(
new ApiKeyCredential(apiKey),
new OpenAIClientOptions { Endpoint = new Uri(endPoint) })
.GetOpenAIResponseClient(model)
.AsIChatClient()
.AsBuilder()
.ConfigureOptions(o =>
{
// Enable reasoning summaries and effort levels
var existingFactory = o.RawRepresentationFactory;
o.RawRepresentationFactory = chatClient =>
{
var rco = existingFactory?.Invoke(chatClient) as ResponseCreationOptions ?? new();
rco.ReasoningOptions = new()
{
ReasoningEffortLevel = rco.ReasoningOptions?.ReasoningEffortLevel ?? ResponseReasoningEffortLevel.Low,
ReasoningSummaryVerbosity = rco.ReasoningOptions?.ReasoningSummaryVerbosity ?? ResponseReasoningSummaryVerbosity.Detailed
};
return rco;
};
})
.Build();
AIAgent agent = new ChatClientAgent(chatClient);
string? responseId = null;
// Ask the first question
await foreach (var update in agent.RunStreamingAsync("What is 1+1?"))
{
responseId = update.ResponseId;
foreach (var item in update.Contents)
{
if (item is TextContent textContent)
{
Console.Write(textContent.Text);
}
}
}
// Ask a follow-up question referencing the last response
await foreach (var update in agent.RunStreamingAsync("What was the last question?", options: new ChatClientAgentRunOptions
{
ChatOptions = new ChatOptions
{
RawRepresentationFactory = _ => new ResponseCreationOptions()
{
PreviousResponseId = responseId,
ReasoningOptions = new()
{
ReasoningEffortLevel = ResponseReasoningEffortLevel.High,
ReasoningSummaryVerbosity = ResponseReasoningSummaryVerbosity.Detailed
}
}
}
}))
{
foreach (var item in update.Contents)
{
if (item is TextContent textContent)
{
Console.Write(textContent.Text);
}
}
}
Run the Application
Before running the application, ensure that LM Studio is running and the OpenAI-compatible API is enabled. Set the necessary environment variables for the API endpoint, API key (for LM Studio, API Key is not needed, however to make it work with other OpenAI APIs, you need to set a dummy one), and model name. You can do this in your terminal:
export OPENAI_ENDPOINT="http://localhost:11435/v1"
export OPENAI_API_KEY="api-Key"
export OPENAI_MODEL="openai/gpt-oss-20b"
Now, run your application:
dotnet run
If configured correctly, you’ll see the agent’s streamed reasoning process:
1+1 = 2
The last question was "What is 1+1?"
Understanding how this example works
Creating the OpenAI Response Client
var chatClient = new OpenAIClient(new ApiKeyCredential(apiKey), new OpenAIClientOptions { Endpoint = new Uri(endPoint) })
.GetOpenAIResponseClient(model)
.AsIChatClient().AsBuilder()
This part does the following:
-
Creates an OpenAI client that connects to either OpenAI’s hosted API or a local LM Studio endpoint.
-
Calls
.GetOpenAIResponseClient(model)to access the Responses API interface, which is different from the traditional Chat Completions API. -
Converts that client into an
IChatClient— a common interface used across the Microsoft Agent framework. -
Calls
.AsBuilder()so you can fluently configure options before finalizing the client.
This design allows you to inject custom configuration logic — which is where ConfigureOptions comes into play.
Configuring Default Response Options with ConfigureOptions
.ConfigureOptions(o =>
{
var existingFactory = o.RawRepresentationFactory;
o.RawRepresentationFactory = chatClient =>
{
var rco = existingFactory?.Invoke(chatClient) as ResponseCreationOptions ?? new();
rco.ReasoningOptions = new()
{
ReasoningEffortLevel = rco.ReasoningOptions?.ReasoningEffortLevel ?? ResponseReasoningEffortLevel.Low,
ReasoningSummaryVerbosity = rco.ReasoningOptions?.ReasoningSummaryVerbosity ?? ResponseReasoningSummaryVerbosity.Detailed
};
return rco;
};
})
.Build();
Here’s what’s happening:
-
ConfigureOptionsallows you to override or extend the default configuration logic used by the chat client. -
The
RawRepresentationFactoryis a delegate that defines how raw request options — in this case,ResponseCreationOptions— are created for each chat request. -
We capture the existing factory (existingFactory) to preserve any prior setup.
-
Then, we wrap it with a new function that:
-
Reuses or initializes a new
ResponseCreationOptionsobject. -
Sets the
ReasoningOptions, which determine how deeply the model reasons and how verbose its reasoning summaries are. -
The
ReasoningEffortLevelcan be Low, Medium, or High, which tells the model how much internal reasoning to apply before producing an answer. -
The
ReasoningSummaryVerbositycontrols how much of that reasoning is shown back in the response stream.
-
In short, ConfigureOptions acts like a global configuration hook — it ensures every request made by the agent uses consistent reasoning settings unless explicitly overridden.
Streaming Responses with Context Memory
await foreach (var update in agent.RunStreamingAsync("What is 1+1?"))
await foreach (var update in agent.RunStreamingAsync("What was the last question?", options: new ChatClientAgentRunOptions { ... }))
- The code uses
RunStreamingAsyncto send a query and receive a stream of incremental updates - Each update also contains a
ResponseId, which you can pass back into later calls usingPreviousResponseIdto preserve conversational context.
This pattern lets your agent “remember” previous responses — making follow-up questions like “What was the last question?” possible even across separate runs.
Currently OpenAI SDK does not support response.reasoning_text.delta which is emitted by gpt-oss, hence reasoning can not be captured directly via SDK. You can learn more about this -
openai/openai-dotnet#748
Conclusion
The Responses API marks a significant step forward in how we build conversational systems — making it easier to embed tool usage, manage state, and handle more sophisticated workflows. LM Studio’s recent adoption of Responses is especially exciting because it brings the same API semantics to local models, letting developers build flexible, portable, hybrid systems.
